Linux 性能监控、测试、优化工具
2014年09月5日 | 标签: benchmarking, linux, monitoring, performance, tuning
Linux 平台上的性能工具有很多,眼花缭乱,长期的摸索和经验发现最好用的还是那些久经考验的、简单的小工具。系统性能专家 Brendan D. Gregg 在最近的 LinuxCon NA 2014 大会上更新了他那个有名的关于 Linux 性能方面的 talk (Linux Performance Tools) 和幻灯片。
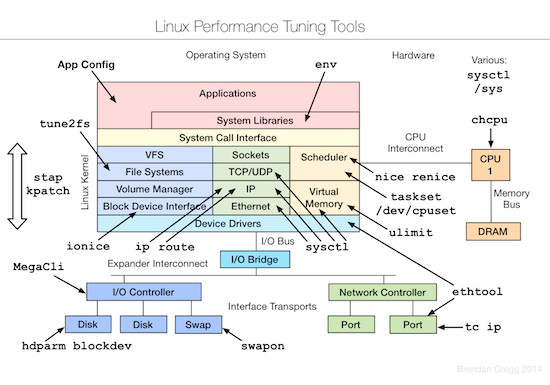
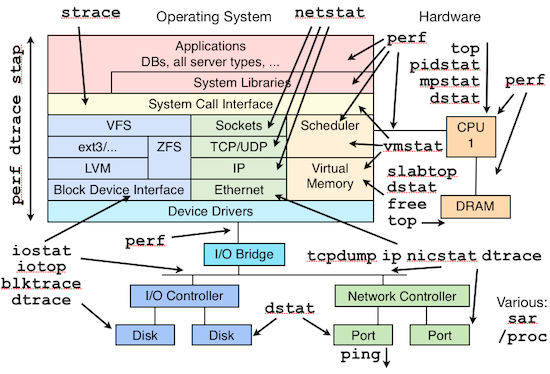
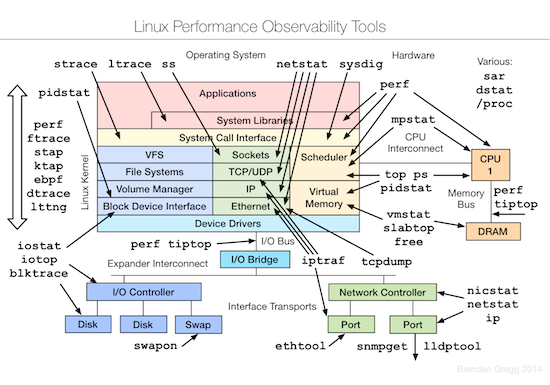
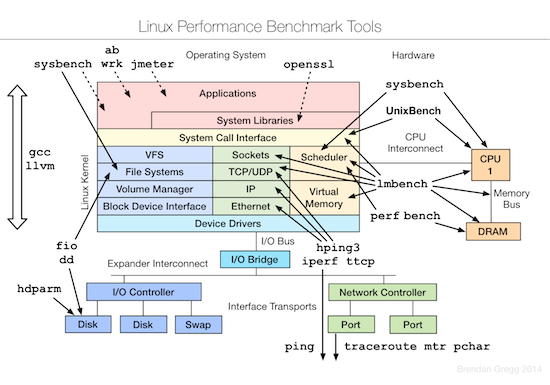
和 Brendan 去年的 talk 比较,今年增加了测试和优化两部分。下面的三张图片分别总结了 Linux 各个子系统以及监控、测试、优化这些子系统所用到的工具。
监控
测试
优化