Netlog 的数据库及 LAMP 架构
2009年07月21日 | 标签: lamp, scaling, sharding | 作者:vpsee
Database Sharding@Netlog 详细的描述了 Netlog 数据库架构的演变过程,文章浅显易懂,非常值得学习。本文数据、图片均来自:Database Sharding at Netlog, with MySQL and PHP
数据
约4000万活跃用户
每月约5000万独立访问
每月约50亿 PV 和 每月 60亿 online minutes
在数据库 sharding 以前,高峰时期每秒3000次以上数据库查询
26种语言,30多个国家,5个最活跃的国家主要集中在欧洲
技术平台
Squid
Lighttpd, Apache
PHP
MySQL
Debian
Memcached
Sphinx
and many more.
Netlog 数据库架构的历史
netlog 从7年前的一个 hobby project 发展而来,数据库从单台服务器扩展到树型多台服务器。
DB Setup 1: Master (W)
读写都在一台服务器上。

DB Setup 2: Master (W) + Slaves (R)
读写分离,写操作(INSERT/UPDATE/DELETE)在 Master 上执行,读操作(SELECT)在1个或者多个 Slaves 上执行。这种方案适合读比写多的情况,比如读写比例4:1的情况,不适合写比读多的情况,比如读写比例1:4。Slaves 通过同步 Master 的 binlog 文件,并且执行其中所有的写操作来同步数据库。这样会带来数据同步的问题,可能会造成数据滞后,比如一个数据刚写在 Master 上,Slaves 还来不及同步就被读取,读取的数据实际上是以前的数据,造成数据滞后。如果数据恰好很重要,比如用户刚换密码(密码写入 Master),然后用新密码登录(从 Slaves 读取密码),会造成密码不一致,导致用户短时间内登录出错。所以在这种需要读取实时数据的时候最好从 Master 直接读取,避免 Slaves 数据滞后现象发生。还好,需要读取实时数据的时候不多,比如用户更改了邮件地址,就没必要马上读取,所以这种 Master-Slaves 架构在多数情况下还是有效的。

DB Setup 3: Vertical Partitioning
DB Setup 2 的架构有个问题,就是能有效应付读多写少的情况,如果读少写多比如读写1:4就不是那么有效了,Slaves 不停的从 Master 那里同步写操作,只是充当数据复制的机器而已, Slaves 没有有效的参与到分担负载的重任中来。所以为了能分担写操作的负载,这个时候需要做 vertical partitioning,把那些没什么联系、不需要 JOINS 操作的表分到不同的服务器上来减轻负担。比如,把一个用户的相关信息(photos, blogs, videos, polls, …)分散到不同的数据库服务器上,然后给每个分散的数据库里都配上1个带有重复信息的表(userids, nicknames, …),这个时候你仍然可以访问用户的相关信息或者按照要求执行 JOINS 操作。下面的图就是这种结构,Messages 和 Friends 配置成 Slaves,以便从 Top Maser 那里同步复制那些带有有用信息的表(userids, nicknames, …)
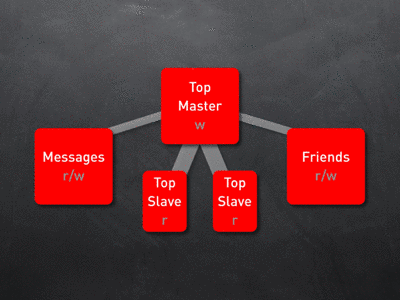
DB Setup 4: Vertical Partitioning / Replication Tree
把 DB Setup 2 和 DB Setup 3 结合起来就成了 DB Setup 4,只要负载过大就配一个或多个 Slaves 给服务器分担负载,这就成了下面的树形结构。
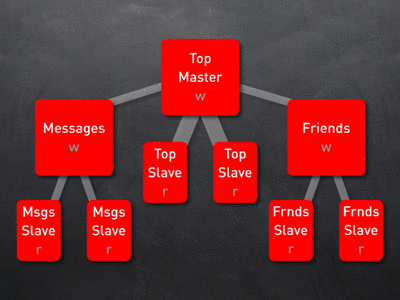
DB Setup 5: Hitting Limits
按照 DB Setup 4 不断深入到应用程序往下加 Slaves,到最后就会变得越来越困难,因为你不断 partition 数据库后你就会发现执行 JOIN 操作就会越来越困难,因为你分出了更多的表。有时候某个表可能会变得超级大以至于服务器处理不了,比如 Friendship 表(用来处理用户关系的表)增长得太快,如果只放在1个 Master 上太危险了,如果 Master 服务器 down 了怎么办?单个 Master 处理性能怎么样?你可以给服务器 scale up,购买更强大更昂贵的服务器,更快的CPU,更大的内存,不过总归不是个办法,迟早还会遇到瓶颈(DB Setup 5)。所以需要更好的 scale out 策略。

DB Setup 6:Sharding
DB Setup 4 的 vertical partitioning 已经帮了很大忙,但是网站继续增长流量继续增大怎么办? Master-Master 行得通不?Cluster 呢?这些方法都是为高可靠性和高性能设计的,对于现在这种需要分载写操作流量的情况不适合。Cache 呢?Cache 可以分担读操作流量,但是对于写操作不会有太大帮助。如果不能 vertical partitioning 了,那能不能 horizontal partitioning 呢?把 DB Setup 4 那张增长迅速、包含1亿条记录的巨大的表(Friendship)水平切成10份,每份1千万条记录,放在10个不同的服务器上。这种技术又可以叫做 sharding,被广泛用于大规模流量的网站上,如 Flickr, LiveJournal, Sun, Netlog 等。

上图把一个 photo 表 shard 到了10台不同的数据库服务器上。但是如何访问这些不同服务器上的数据呢,怎么能知道某个数据放在哪个服务器上呢?用一个小算法(userid % 10),只要知道了用户 userid,就可以知道用户的 photo 放在哪个数据库服务器上,然后连接那台数据库查询。
举一个简单例子,创建一个巨大的 photo 表,其中包含 photoid, title, description, dateadded, authorid,url 列,其中 authorid 是另外一个 user 表(userid, name, …) 的 foreign key。我们将把这张巨大的 photo 表 shard 到2台不同的数据库服务器上,用户 authorid 为奇数的就访问数据库1,authorid 为偶数就访问数据库2。
如果只有1台数据库服务器,不做 shard,访问数据库应该是这个样子:
PHP:
$db = DB::getInstance();
$db->prepare(“SELECT title, url, description FROM photo WHERE userid = {userID}”);
$db->assignInt(‘userID’, $userID);
$db->execute();
$results = $db->getResults();
如果用2台数据库服务器来做 shard,我们需要传一个参数给 DB 类,以便 DB 类知道连接到哪个数据库,比如传 $userID 给 DB::getInstance(),然后 getInstance() 计算 $userID % 2 后返回数据库的连接信息:
PHP:
$db = DB::getInstance($userID);
$db->prepare(“SELECT title, url, description FROM photo WHERE userid = {userID}”);
$db->assignInt(‘userID’, $userID);
$db->execute();
$results = $db->getResults();
Netlog 提到了 shard 数据需要注意的两点:
1、根据数据表的哪个列(如上面的 userid)来切分数据,使数据存到对应的数据库;
2、用什么算法来判断(如上面的 userid % 2)数据存到哪个服务器上。
如何根据数据表来切分数据主要依据程序来决定,Netblog选择的是用户 ID。以下有4种切分数据的方式可以参考:
1、Vertical Partitioning:如 DB Setup 3 那样;
2、Range-based Partitioning:如前1000个用户的信息存在服务器1,1001-2000存在服务器2,…;
3、Key or Hash based Partitioning:如上面的 userid % 2 的例子就是最简单的 key/hash;
4、Directory based Partitioning:最灵活的方式,把 key 和数据库服务器的对应关系保存下来,通过查找的方式找到对应的服务器。
DB Setup 7:Now
Netlog 在应用和数据库之间加了一个中间层,从 PHP 角度看有两部分组成,一部分是用来管理和维护,增加、删除、编辑 shards,数据库,lookup 系统;另一部分用来给数据库层和缓存层提供可以访问的 API。

Shards live in databases, databases live on hosts
Netlog 用的是方式4:Directory based Partitioning,用一个单独的 MySQL 表存放目录 lookup 信息,用来把 $userID(shard keys)映射到对应的 $shardIDs 上,然后通过一些配置文件把 $shardIDs 映射到对应的数据库服务器上(得到相关数据库服务器的连接信息),以便后续操作在对应的数据库上执行。
举个例子来说明如何在 shards 上获取 userid 为26的 photo 信息 :
Query: Give me the photos from author with id 26.
Where is user 26?
User 26 is on shard 5 (26 % 10 -1).
On shard 5; Give me all the $photoIDs ($itemIDs) of user 26.
That user’s $photoIDs are: array(10,12,30);
On shard 5; Give me all details about the items array(10,12,30) of user 26.
Those items are: array(array(‘title’ => “foo”, ‘description’ => “bar”), array(‘title’ => “milk”, ‘description’ => “cow”));
总结
“Don’t do it, if you don’t need to!” (37signals.com)
“Shard early and often!” (startuplessonslearned.blogspot.com)
作者在原文谈到了这两个看上去矛盾的观点。能不 shard 就尽量不 shard,因为 shard 会带来复杂性,数据库变复杂,服务器变多,难以维护、监测等。过分 shard 数据后,关系型数据库带来的好处就没了。尽量用简单的办法解决负载问题,比如:better hardware, more hardware, server tweaking and tuning, vertical partitioning, sql query optimization 等,如果这些能解决问题就不要shard。
另一方面,如果确定有 shard 的必要就要尽早开始设计,并且经常 shard,在设计数据库的时候牢记 shard 的两个关键点 sharding/partitioning key 和 sharding/partitioning scheme。
which property of the data (which column of the table) will I use to make the decisions on where the data should go?
And what will the algorithm be?
阅读了,好文。转载了^_^
[…] Netlog 的数据库及 LAMP 架构 […]
谢谢分享!正在学习大型网站架构。
这个网站并不是很流行呀,虽然总部就在我现在所在的城市。
中国大陆好像也是能访问的,少有的几个。