Craigslist 的 LAMP 架构
2009年09月14日 | 标签: architecture, lamp
关于 Craigslist 的介绍以及一些访问量多大、负载多强大的数据就省略了,VPSee 关心的是背后的技术架构,主要参考文章:MySQL and Sphinx at Craigslist 和 Database War Stories #5: craigslist.
架构
硬件环境: Supermicro 4U 7043-P8、Dual Intel Xeon 3.2 512KB CPU、16GB 内存、16个硬盘组成的 Raid 10;
软件系统: Suse Linux 操作系统,网站大部分用 Perl 编写,使用标准的 LAMP 组合,memcached 做缓存,使用 Sphinx 全文搜索。
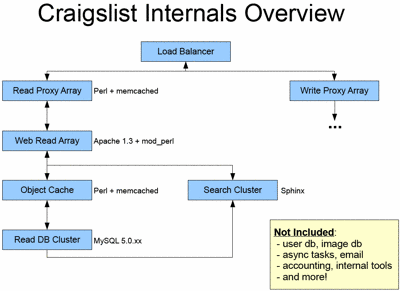
数据库
所有数据库服务器都运行 64 位的 Linux,每个服务器有 16GB 内存和16个硬盘。几台数据库服务器组成一个 db cluster,每个 db cluster 运行一个 Craigslist 服务。
forums:1个 master + 1个 slave,slave 主要用来备份,表使用 myIsam 引擎,DataDir 大小达到 17GB(包括索引在内),最大一个表有近4200万行。
classifeds:1个 master + 12个 slaves,多种不同用途的 slaves,其中 teamreader, longreader, thrashbox 用来备份以及一些非常耗时的特殊查询。还有1个离线 slave 以应付突发情况,比如 colo 崩溃了。其中数据库容积达到 114G(包括索引),最大一个表达到5600万条记录,数据表也是使用 myIsam 引擎。
archivedb:1个 master + 1个 slave,用来归档那些时间超过3个月的帖子,除了比上面的 classifeds 存的数据量大以外,其结构非常类似 classifeds,238G 的数据,9600万条记录。不同的是数据表使用的是 mrg_mylsam,MySQL 的 merge 引擎,方便把 archive 上分散的数据 merge 成更容易管理的块。这也是 merge 表的好处,这里一张表,那里一张表不方便管理,合成一张表更容易管理一些,不过 merge 引擎要求相似的表才能 merge,不是随便什么表都可以 merge 的。
searchdbs:4个 clusters(16台服务器),把 live 的帖子按照 area/category 切分,每个 cluster 只包含 一部分的 live 帖子,使用 myIsam 全文索引。不过要注意的是,全文索引(Indexing)很耗资源,很烧钱。
authdb:1个 master + 1个 slave,这个最小了,只是存一些临时、短暂的数据(transient data)。
MySQL 似乎在 64 位的机器上运行得更好一些。
全文搜索
Craigslist 刚开始使用了 MySQL 全文搜索(Full text indexing and searching),随着规模变大,MySQL 全文搜索逐渐不能应付要求,不能 scale,改用 Sphinx 做搜索,一段时间后发现 Sphinx 也不能满足需求,不能 scale,最后不得不 patch sphinx 以满足日益增长的庞大数据库和搜索需求。Craigslist 的经验是,在一张很大的表上做全文索引和搜索是行不通的,因为用户没有耐心去等待漫长的搜索过程,搜索结果往往不能在用户期望的时间内返回。