在 CentOS 7.1 上安装分布式存储系统 Ceph
2015年07月31日 | 标签: ceph, storage
关于 Ceph 的介绍网上一大堆,这里就不重复了。Sage Weil 读博士的时候开发了这套牛逼的分布式存储系统,最初是奔着高性能分布式文件系统去的,结果云计算风口一来,Ceph 重心转向了分布式块存储(Block Storage)和分布式对象存储(Object Storage),现在分布式文件系统 CephFS 还停在 beta 阶段。Ceph 现在是云计算、虚拟机部署的最火开源存储解决方案,据说有20%的 OpenStack 部署存储用的都是 Ceph 的 block storage.
Ceph 提供3种存储方式:对象存储,块存储和文件系统,下图很好的展示了 Ceph 存储集群的架构:
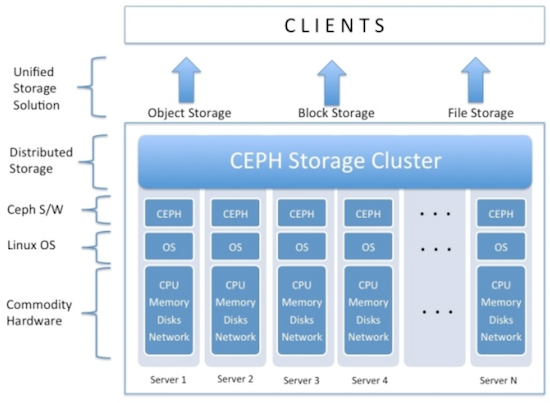
我们主要关心的是块存储,将在下半年慢慢把虚拟机后端存储从 SAN 过渡到 Ceph. 虽然还是 0.94 版本,Ceph 现在已经比较成熟了,有个同事已经在生产环境里运行 Ceph 了两年多,他曾遇到很多问题,但最终还是解决了,可见 Ceph 还是非常稳定和可靠的。
硬件环境准备
准备了6台机器,其中3台物理服务器做监控节点(mon: ceph-mon1, ceph-mon2, ceph-mon3),2台物理服务器做存储节点(osd: ceph-osd1, ceph-osd2),1台虚拟机做管理节点(adm: ceph-adm)。
Ceph 要求必须是奇数个监控节点,而且最少3个(自己玩玩的话,1个也是可以的),ceph-adm 是可选的,可以把 ceph-adm 放在 monitor 上,只不过把 ceph-adm 单独拿出来架构上看更清晰一些。当然也可以把 mon 放在 osd 上,生产环境下是不推荐这样做的。
- ADM 服务器硬件配置比较随意,用1台低配置的虚拟机就可以了,只是用来操作和管理 Ceph;
- MON 服务器2块硬盘做成 RAID1,用来安装操作系统;
- OSD 服务器上用10块 4TB 硬盘做 Ceph 存储,每个 osd 对应1块硬盘,每个 osd 需要1个 Journal,所以10块硬盘需要10个 Journal,我们用2块大容量 SSD 硬盘做 journal,每个 SSD 等分成5个区,这样每个区分别对应一个 osd 硬盘的 journal,剩下的2块小容量 SSD 装操作系统,采用 RAID1.
配置列表如下:
| Hostname | IP Address | Role | Hardware Info | |-----------+---------------+-------|---------------------------------------------------------| | ceph-adm | 192.168.2.100 | adm | 2 Cores, 4GB RAM, 20GB DISK | | ceph-mon1 | 192.168.2.101 | mon | 24 Cores,64GB RAM, 2x750GB SAS | | ceph-mon2 | 192.168.2.102 | mon | 24 Cores,64GB RAM, 2x750GB SAS | | ceph-mon3 | 192.168.2.103 | mon | 24 Cores,64GB RAM, 2x750GB SAS | | ceph-osd1 | 192.168.2.121 | osd | 12 Cores,64GB RAM, 10x4TB SAS,2x400GB SSD,2x80GB SSD | | ceph-osd2 | 192.168.2.122 | osd | 12 Cores,64GB RAM, 10x4TB SAS,2x400GB SSD,2x80GB SSD |
软件环境准备
所有 Ceph 集群节点采用 CentOS 7.1 版本(CentOS-7-x86_64-Minimal-1503-01.iso),所有文件系统采用 Ceph 官方推荐的 xfs,所有节点的操作系统都装在 RAID1 上,其他的硬盘单独用,不做任何 RAID.
安装完 CentOS 后我们需要在每个节点上(包括 ceph-adm 哦)做一点基本配置,比如关闭 SELINUX、打开防火墙端口、同步时间等:
关闭 SELINUX # sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config # setenforce 0 打开 Ceph 需要的端口 # firewall-cmd --zone=public --add-port=6789/tcp --permanent # firewall-cmd --zone=public --add-port=6800-7100/tcp --permanent # firewall-cmd --reload 安装 EPEL 软件源: # rpm -Uvh https://dl.fedoraproject.org/pub/epel/7/x86_64/e/epel-release-7-5.noarch.rpm # yum -y update # yum -y upgrade 安装 ntp 同步时间 # yum -y install ntp ntpdate ntp-doc # ntpdate 0.us.pool.ntp.org # hwclock --systohc # systemctl enable ntpd.service # systemctl start ntpd.service
在每台 osd 服务器上我们需要对10块 SAS 硬盘分区、创建 xfs 文件系统;对2块用做 journal 的 SSD 硬盘分5个区,每个区对应一块硬盘,不需要创建文件系统,留给 Ceph 自己处理。
# parted /dev/sda
GNU Parted 3.1
Using /dev/sda
Welcome to GNU Parted! Type 'help' to view a list of commands.
(parted) mklabel gpt
(parted) mkpart primary xfs 0% 100%
(parted) quit
# mkfs.xfs /dev/sda1
meta-data=/dev/sda1 isize=256 agcount=4, agsize=244188544 blks
= sectsz=4096 attr=2, projid32bit=1
= crc=0 finobt=0
data = bsize=4096 blocks=976754176, imaxpct=5
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=0
log =internal log bsize=4096 blocks=476930, version=2
= sectsz=4096 sunit=1 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
...
上面的命令行要对10个硬盘处理,重复的操作太多,以后还会陆续增加服务器,写成脚本 parted.sh 方便操作,其中 /dev/sda|b|d|e|g|h|i|j|k|l 分别是10块硬盘,/dev/sdc 和 /dev/sdf 是用做 journal 的 SSD:
# vi parted.sh
#!/bin/bash
set -e
if [ ! -x "/sbin/parted" ]; then
echo "This script requires /sbin/parted to run!" >&2
exit 1
fi
DISKS="a b d e g h i j k l"
for i in ${DISKS}; do
echo "Creating partitions on /dev/sd${i} ..."
parted -a optimal --script /dev/sd${i} -- mktable gpt
parted -a optimal --script /dev/sd${i} -- mkpart primary xfs 0% 100%
sleep 1
#echo "Formatting /dev/sd${i}1 ..."
mkfs.xfs -f /dev/sd${i}1 &
done
SSDS="c f"
for i in ${SSDS}; do
parted -s /dev/sd${i} mklabel gpt
parted -s /dev/sd${i} mkpart primary 0% 20%
parted -s /dev/sd${i} mkpart primary 21% 40%
parted -s /dev/sd${i} mkpart primary 41% 60%
parted -s /dev/sd${i} mkpart primary 61% 80%
parted -s /dev/sd${i} mkpart primary 81% 100%
done
# sh parted.sh
在 ceph-adm 上运行 ssh-keygen 生成 ssh key 文件,注意 passphrase 是空,把 ssh key 拷贝到每一个 Ceph 节点上:
# ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: # ssh-copy-id root@ceph-mon1 # ssh-copy-id root@ceph-mon2 # ssh-copy-id root@ceph-mon3 # ssh-copy-id root@ceph-osd1 # ssh-copy-id root@ceph-osd2
在 ceph-adm 上登陆到每台节点上确认是否都能无密码 ssh 了,确保那个烦人的连接确认不会再出现:
# ssh root@ceph-mon1 The authenticity of host 'ceph-mon1 (192.168.2.101)' can't be established. ECDSA key fingerprint is d7:db:d6:70:ef:2e:56:7c:0d:9c:62:75:b2:47:34:df. Are you sure you want to continue connecting (yes/no)? yes # ssh root@ceph-mon2 # ssh root@ceph-mon3 # ssh root@ceph-osd1 # ssh root@ceph-osd2
Ceph 部署
比起在每个 Ceph 节点上手动安装 Ceph,用 ceph-deploy 工具统一安装要方便得多:
# rpm -Uvh http://ceph.com/rpm-hammer/el7/noarch/ceph-release-1-1.el7.noarch.rpm # yum update -y # yum install ceph-deploy -y
创建一个 ceph 工作目录,以后的操作都在这个目录下面进行:
# mkdir ~/ceph-cluster # cd ~/ceph-cluster
初始化集群,告诉 ceph-deploy 哪些节点是监控节点,命令成功执行后会在 ceph-cluster 目录下生成 ceph.conf, ceph.log, ceph.mon.keyring 等相关文件:
# ceph-deploy new ceph-mon1 ceph-mon2 ceph-mon3
在每个 Ceph 节点上都安装 Ceph:
# ceph-deploy install ceph-adm ceph-mon1 ceph-mon2 ceph-mon3 ceph-osd1 ceph-osd2
初始化监控节点:
# ceph-deploy mon create-initial
查看一下 Ceph 存储节点的硬盘情况:
# ceph-deploy disk list ceph-osd1 # ceph-deploy disk list ceph-osd2
初始化 Ceph 硬盘,然后创建 osd 存储节点,存储节点:单个硬盘:对应的 journal 分区,一一对应:
创建 ceph-osd1 存储节点 # ceph-deploy disk zap ceph-osd1:sda ceph-osd1:sdb ceph-osd1:sdd ceph-osd1:sde ceph-osd1:sdg ceph-osd1:sdh ceph-osd1:sdi ceph-osd1:sdj ceph-osd1:sdk ceph-osd1:sdl # ceph-deploy osd create ceph-osd1:sda:/dev/sdc1 ceph-osd1:sdb:/dev/sdc2 ceph-osd1:sdd:/dev/sdc3 ceph-osd1:sde:/dev/sdc4 ceph-osd1:sdg:/dev/sdc5 ceph-osd1:sdh:/dev/sdf1 ceph-osd1:sdi:/dev/sdf2 ceph-osd1:sdj:/dev/sdf3 ceph-osd1:sdk:/dev/sdf4 ceph-osd1:sdl:/dev/sdf5 创建 ceph-osd2 存储节点 # ceph-deploy disk zap ceph-osd2:sda ceph-osd2:sdb ceph-osd2:sdd ceph-osd2:sde ceph-osd2:sdg ceph-osd2:sdh ceph-osd2:sdi ceph-osd2:sdj ceph-osd2:sdk ceph-osd2:sdl # ceph-deploy osd create ceph-osd2:sda:/dev/sdc1 ceph-osd2:sdb:/dev/sdc2 ceph-osd2:sdd:/dev/sdc3 ceph-osd2:sde:/dev/sdc4 ceph-osd2:sdg:/dev/sdc5 ceph-osd2:sdh:/dev/sdf1 ceph-osd2:sdi:/dev/sdf2 ceph-osd2:sdj:/dev/sdf3 ceph-osd2:sdk:/dev/sdf4 ceph-osd2:sdl:/dev/sdf5
最后,我们把生成的配置文件从 ceph-adm 同步部署到其他几个节点,使得每个节点的 ceph 配置一致:
# ceph-deploy --overwrite-conf admin ceph-adm ceph-mon1 ceph-mon2 ceph-mon3 ceph-osd1 ceph-osd2
测试
看一下配置成功了没?
# ceph health HEALTH_WARN too few PGs per OSD (10 < min 30)
增加 PG 数目,根据 Total PGs = (#OSDs * 100) / pool size 公式来决定 pg_num(pgp_num 应该设成和 pg_num 一样),所以 20*100/2=1000,Ceph 官方推荐取最接近2的指数倍,所以选择 1024。如果顺利的话,就应该可以看到 HEALTH_OK 了:
# ceph osd pool set rbd size 2 set pool 0 size to 2 # ceph osd pool set rbd min_size 2 set pool 0 min_size to 2 # ceph osd pool set rbd pg_num 1024 set pool 0 pg_num to 1024 # ceph osd pool set rbd pgp_num 1024 set pool 0 pgp_num to 1024 # ceph health HEALTH_OK
更详细一点:
# ceph -s
cluster 6349efff-764a-45ec-bfe9-ed8f5fa25186
health HEALTH_OK
monmap e1: 3 mons at {ceph-mon1=192.168.2.101:6789/0,ceph-mon2=192.168.2.102:6789/0,ceph-mon3=192.168.2.103:6789/0}
election epoch 6, quorum 0,1,2 ceph-mon1,ceph-mon2,ceph-mon3
osdmap e107: 20 osds: 20 up, 20 in
pgmap v255: 1024 pgs, 1 pools, 0 bytes data, 0 objects
740 MB used, 74483 GB / 74484 GB avail
1024 active+clean
如果操作没有问题的话记得把上面操作写到 ceph.conf 文件里,并同步部署的各节点:
# vi ceph.conf [global] fsid = 6349efff-764a-45ec-bfe9-ed8f5fa25186 mon_initial_members = ceph-mon1, ceph-mon2, ceph-mon3 mon_host = 192.168.2.101,192.168.2.102,192.168.2.103 auth_cluster_required = cephx auth_service_required = cephx auth_client_required = cephx filestore_xattr_use_omap = true osd pool default size = 2 osd pool default min size = 2 osd pool default pg num = 1024 osd pool default pgp num = 1024 # ceph-deploy admin ceph-adm ceph-mon1 ceph-mon2 ceph-mon3 ceph-osd1 ceph-osd2
如果一切可以从来
部署过程中如果出现任何奇怪的问题无法解决,可以简单的删除一切从头再来:
# ceph-deploy purge ceph-mon1 ceph-mon2 ceph-mon3 ceph-osd1 ceph-osd2 # ceph-deploy purgedata ceph-mon1 ceph-mon2 ceph-mon3 ceph-osd1 ceph-osd2 # ceph-deploy forgetkeys
Troubleshooting
如果出现任何网络问题,首先确认节点可以互相无密码 ssh,各个节点的防火墙已关闭或加入规则:
# ceph health 2015-07-31 14:31:10.545138 7fce64377700 0 -- :/1024052 >> 192.168.2.101:6789/0 pipe(0x7fce60027050 sd=3 :0 s=1 pgs=0 cs=0 l=1 c=0x7fce60023e00).fault HEALTH_OK # ssh ceph-mon1 # firewall-cmd --zone=public --add-port=6789/tcp --permanent # firewall-cmd --zone=public --add-port=6800-7100/tcp --permanent # firewall-cmd --reload # ceph health HEALTH_OK
初次安装 Ceph 会遇到各种各样的问题,总体来说排错还算顺利,随着经验的积累,今年下半年将会逐步把 Ceph 加入到生产环境。