轻量级 Linux 桌面发行版 CrunchBang
2013年08月1日 | 标签: crunchbang, linux, openbox
这周拿到一台新笔记本,很久没摸过 PC 忽然发现自己彻底 out 了。开机预装的是 Windows 8,界面飞来飞去,想看看配置不知道怎么去控制面板,花了两分钟没找到关机菜单,直接电源长按强制关机,重启后准备安装 Linux,发现现在流行什么 UEFI,无法装 Linux,一顿搜索发现需要在 BIOS 里换成 Legacy …
朋友推荐的 CrunchBang 用了几天感觉非常棒,这才是一个系统应该有的嘛,轻量级、不过分占用资源,界面低调简洁,默认软件都已经精心挑选,装完系统后立刻可用(对于我的需求来说),不需要 “安装完 … 后必做的10件事”,…,相信有类似喜好(minimalism & simplicity)的 Linux 爱好者都会喜欢。
安装完后的桌面:
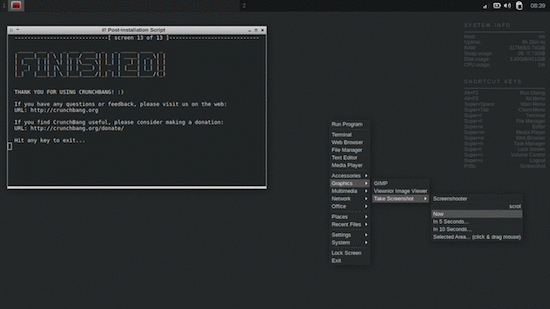
CrunchBang 是一款基于 Debian GNU/Linux、使用 Openbox 作为窗口管理器的轻量级 Linux 桌面发行版。界面看上去简洁、优雅,符合个人喜好;系统符合轻量级的要求,占用资源少、速度快;软件选择上偏向轻量级,默认安装好的软件多是自己常用的,省了自己安装和配置的时间;细节上 CrunchBang 处理也很到位,桌面已经配置好 SYSTEM INFO(有人喜欢在桌面或者任务栏看到系统资源占用情况),桌面还有个 SHORTCUT KEYS 用来帮助新手记住一些常用快捷键。按照自己使用电脑的习惯,CrunchBang 安装完后就基本可用,无线网络、外接显示器、打印机、多窗口、Google Chrome 浏览器、Terminal 分屏显示等等这些我要用到的统统默认,无需更多配置,简直就是 “我” 的发行版。
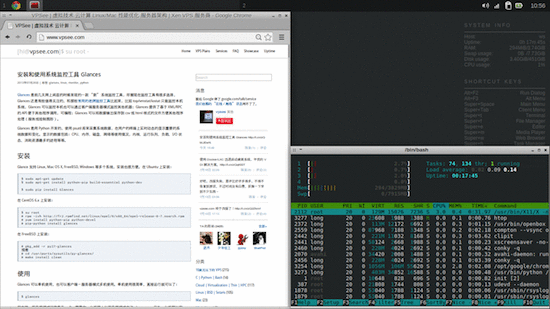
Chrome 浏览器和 Terminal:
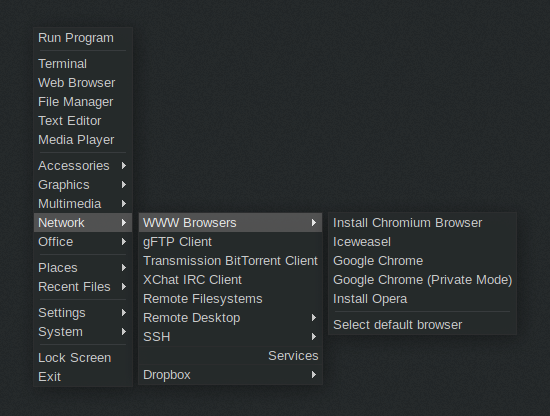
近距离看菜单和背景,个人挺喜欢的风格:
有个小问题就是选择安装英文版系统的话不会默认安装中文字体,这样中文网页打开看到的是方块,所以想看中文的话需要安装个中文字体:
$ sudo apt-get update $ sudo apt-get install ttf-wqy-microhei