Pinboard 的 PHP/MySQL 架构
2011年03月14日 | 标签: architecture, mysql, perl, php, sphinx
Pinboard 是一个提供在线书签服务的网站,和 Delicious 类似,不同的是 Pinboard 不是免费的,而且是从一开始就收费——采用有趣的渐进式收费,也就是说每增加一个人、后来的人就需多付0.001美元(按照 number of users * 0.001 的公式),这样的收费方式利用了人们的 “趁便宜赶快买,明天会更贵” 的心理,提供了一套独特的收费模式。让 VPSee 惊讶的是他们背后的技术出奇的简单,没有 Fotolog 那种 MySQL 集群+Memcached 集群,也没有 Netlog 那么复杂的数据库切分。在他们的 About 页面上,这位来自罗马利亚的创始人说:
Pinboard is written in PHP and Perl. The site uses MySQL for data storage, Sphinx for search, and Amazon S3 to store backups. There is absolutely nothing interesting about the Pinboard architecture or implementation; I consider that a feature!
数据
1亿6千多万个书签
5200多万个标签
9400多万个 urls
989 GB 的数据
平台
MySQL
PHP
Perl
Ubuntu
APC
Sphinx
Cron jobs
Amazon S3
硬件
服务器 1:64 GB, 主数据库(master),用来存储用户数据和搜索;
服务器 2:32 GB, 备用主数据库(failover master),用来爬 feeds 等一些后台任务
服务器 3:16 GB, web 服务器和从数据库(slave)
另外提一下,他们租用的这三台服务器有两台是从 DigitalOne 租用的,还有一台是从 ServerBeach 租的。
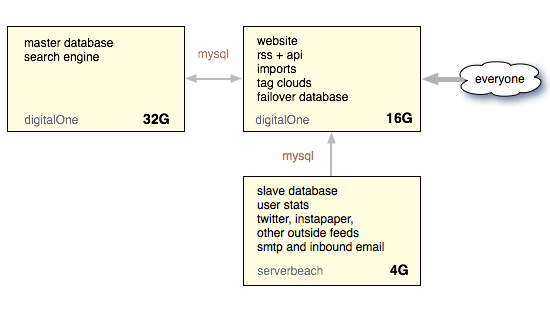
架构
- 他们运行的是 Ubuntu 操作系统;
- 每台服务器上(一共3台)均保留一份整体数据库的拷贝;
- 网站运行在 16GB 的服务器上,数据库完全放在内存里,页面装载时间提高了10倍;
- 采用 master-master 数据库架构加上一个只读的 slave,所有写操作都在一个数据库上进行,第二个 master 数据库服务器主要用来计算,比如统计全局链接数,用户统计等;每天晚上数据库用 mysqldump 备份,然后备份的数据以压缩的形式储存在 Amazon S3 上。
- Perl 脚本用来运行后台任务,比如下载 feeds、缓存页面、处理 email、生成 tag 云标签、备份数据等。他们选择 Perl 的理由是因为自己很熟悉而且有大量的库可以使用。像 “最受欢迎的书签” 这样的功能一般都是在晚上里通过后台的定时任务(cron job)完成。PHP 用来生成 HTML 页面,没有使用任何 templating engine,也没有使用任何框架(framework)。APC 用来做 PHP 缓存,没有用其他缓存技术,Sphinx 用来做搜索引擎。
经验
- 使用成熟、老掉牙的技术,这样保证网站和程序运行快而且不会因为软件 bug 丢失数据。(VPSee 非常赞同这点,使用简单和可以理解的技术,我们相信技术是拿来用的,不是拿来炫的。)
- 保持小规模会有趣得多,当你自己亲自提供客服支持和与客户打交道的时候你会发现很有价值;
- 服务器成本用每 GB 内存(或存储)的价格来衡量,Pinboard 最初使用的是 Linode 和 Slicehost 的 VPS,后来发现 VPS 不够用,随着内存增大 VPS 越来越贵,价格不如独立服务器。(按照 VPSee 的个人经验,低端(<= 4GB)用 VPS 划算、高端(>=16GB)用独立服务器划算。)
- 按照服务划分服务器,比如 web 服务器就拿来做 web 服务器,最好不要拿来干别的。