在 FreeBSD 10 上搭建 Time Machine 备份服务
2015年09月22日 | 标签: freebsd, time machine
Backblaze 是一家在线存储服务商,每隔一段时间他们就会发布他们的存储服务器 Storage Pod 设计细节(Storage Pod 4.5),一些第三方公司就按照这个设计造出一些廉价的存储服务器来出售。
没调查清楚头脑一热就买了,买回来拆开一看有点后悔:
- 只有一个系统盘,OS 装在一个盘上太危险,至少应该双硬盘 RAID1;
- 只有一个电源,服务器系统至少需要配用2个可用电源;
- 没有硬件 RAID,这个无所谓,我们也不打算用 RAID;
- 只有2个 GigE 网卡,我们购买了额外2个 10 GigE;
- 开箱操作不方便,更换一个硬盘每次都要把10几个螺丝钉卸下来;
- 没有硬盘指示灯,哪个硬盘坏了无法从45个硬盘里迅速识别出来。
……

不过我们对这台存储服务器没太多要求,主要做归档备份用,不是我们的主备份,也不太在乎它是否可靠,所以先凑合着用吧。两年前我们提到 “把 Time Machine 备份到 FreeNAS 上”,FreeNAS 现在变得有点臃肿,官方要求最小 8GB 内存,推荐最小 16GB 内存,这次打算直接用 FreeBSD + ZFS.
ZFS 准备工作
我们选择 FreeBSD 做备份的主要原因就是因为 ZFS,ZFS 操作起来太方便了。把30个硬盘连起来创建一个叫做 backup 的大存储池,采用 raidz2(相当于 RAID6):
# zpool create backup raidz2 /dev/da0 /dev/da1 /dev/da2 /dev/da3 /dev/da4 /dev/da5 /dev/da6 /dev/da7 /dev/da8 /dev/da9 /dev/da10 /dev/da11 /dev/da12 /dev/da13 /dev/da14 /dev/da15 / dev/da16 /dev/da17 /dev/da18 /dev/da19 /dev/da20 /dev/da21 /dev/da22 /dev/da23 /dev/da24 /dev/da25 /dev/da26 /dev/da27 /dev/da28 /dev/da29
在 pool 上创建一个文件系统 timemachine,创建好后就自动挂载好了,不用再手动 mount:
# zfs create backup/timemachine # df -h Filesystem Size Used Avail Capacity Mounted on /dev/ada0p2 447G 2.3G 409G 1% / devfs 1.0K 1.0K 0B 100% /dev backup 31T 278K 31T 0% /backup backup/timemachine 31T 1.0G 31T 0% /backup/timemachine
对每个使用 Mac/Time Machine 的用户需要在 FreeBSD 系统上增加一个对应的帐户,并把帐户加到 timemachine 组里面便于统一管理:
# pw useradd -n vpsee -s /bin/csh -m # passwd vpsee # pw groupadd timemachine # pw groupmod timemachine -m vpsee # pw groupshow timemachine timemachine:*:1002:vpsee
在 /backup/timemachine 下面新建一个用户目录,并给予适当权限:
# mkdir /backup/timemachine/vpsee # chown vpsee:timemachine /backup/timemachine/vpsee # chmod 700 /backup/timemachine/vpsee # chmod 777 /backup/timemachine
安装和配置 Netatalk
Netatalk 是一个开源的 AFP (Apple File Protocol) 文件服务器,为 Mac OS X 提供文件共享服务。Avahi 是 Apple Zeroconf 协议的开源实现,类似 Bonjour 的功能,它可以让你在 Mac 系统里自动发现你的 FreeBSD 服务器。我们直接使用 pkg 安装软件包:
# pkg install netatalk3 # pkg install nss_mdns # pkg install avahi
修改 nsswitch.conf:
# vi /etc/nsswitch.conf # # nsswitch.conf(5) - name service switch configuration file # $FreeBSD: releng/10.2/etc/nsswitch.conf 224765 2011-08-10 20:52:02Z dougb $ # ... hosts: files dns mdns ...
配置 afp:
# vi /usr/local/etc/afp.conf ; ; Netatalk 3.x configuration file ; [Global] vol preset = default_for_all_vol log file = /var/log/netatalk.log log level = default:info hosts allow = 172.20.0.0/23 mimic model = TimeCapsule6,116 disconnect time = 1 [default_for_all_vol] file perm = 0640 directory perm = 0750 cnid scheme = dbd [TimeMachine] time machine = yes path=/backup/timemachine/$u valid users = @timemachine #512 GB limit vol size limit = 512000
配置完后启动各服务:
# /usr/local/etc/rc.d/dbus onestart # /usr/local/etc/rc.d/avahi-daemon onestart # /usr/local/etc/rc.d/netatalk onestart
如果测试后都好用的话别忘了把服务加到启动文件里:
# vi /etc/rc.conf ... zfs_enable="YES" dbus_enable="YES" avahi_daemon_enable="YES" avahi_dnsconfd_enable="YES" netatalk_enable="YES" ...
Mac 配置
在 Mac 上把这个选项打开:
$ defaults write com.apple.systempreferences TMShowUnsupportedNetworkVolumes 1
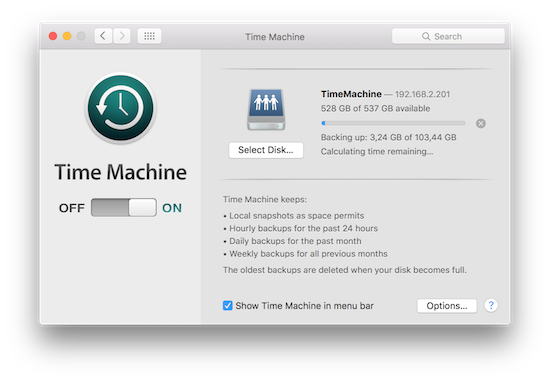
打开 Finder -> Go -> Connect to Server… 填入 FreeBSD 的 IP 地址(afp://192.168.2.201)后点击 Connect,使用刚才创建的帐号和密码登录进入之后就会看到 TimeMachine 文件夹。
打开 System Preferences -> Time Machine -> On 选择 TimeMachine 文件夹,然后点击 Use Disk 就应该能用了。