使用 Flask 搭建静态博客
2014年10月15日 | 标签: flask, python
现在流行的静态博客/网站生成工具有很多,比如 Jekyll, Pelican, Middleman, Hyde 等等,StaticGen 列出了目前最流行的一些静态网站生成工具。
我们的内部工具由 Python/Flask/MongoDB 搭建,现在需要加上文档功能,写作格式是 Markdown,不想把文档放到数据库里,也不想再弄一套静态博客工具来管理文档,于是找到了 Flask-FlatPages 这个好用的 Flask 模块。熟悉 Flask 的同学花几分钟的时间就可以用搭建一个简单博客,加上 Bootstrap 的帮助,不到一小时内就可以用 Flask-Flatpages 弄个像模像样的网站出来。
创建开发环境
首先我们需要 pip,在 Mac 上最简单的安装办法是:
$ sudo easy_install pip $ sudo easy_install virtualenv
如果你在 Mac 上用 Homebrew 包管理工具的话的话,也可以用 brew 升级 Python 和安装 pip:
$ brew update $ brew install python
创建一个 blog 目录、生成 Python 独立虚拟环境并在这个环境里安装需要的 Flask, Flask-FlatPages 模块:
$ mkdir blog $ cd blog $ virtualenv flask New python executable in flask/bin/python Installing setuptools, pip...done. $ flask/bin/pip install flask $ flask/bin/pip install flask-flatpages
在 blog 目录下我们分别新建几个目录:static 用来存放 css/js 等文件,templates 用来存放 flask 要用的 Jinja2 模版,pages 用来存放我们静态博客(Markdown 格式):
$ mkdir -p app/static app/templates app/pages
程序
主程序 blog.py 的功能是,导入必要的模块、配置 Flask-FlatPages 模块需要的参数、创建 Flask 应用、写几个 URL 路由函数,最后运行这个应用:
$ vi app/blog.py
#!flask/bin/python
from flask import Flask, render_template
from flask_flatpages import FlatPages
DEBUG = True
FLATPAGES_AUTO_RELOAD = DEBUG
FLATPAGES_EXTENSION = '.md'
app = Flask(__name__)
app.config.from_object(__name__)
flatpages = FlatPages(app)
@app.route('/')
def index():
pages = (p for p in flatpages if 'date' in p.meta)
return render_template('index.html', pages=pages)
@app.route('/pages/<path:path>/')
def page(path):
page = flatpages.get_or_404(path)
return render_template('page.html', page=page)
if __name__ == '__main__':
app.run(port=8000)
模版
在 Python 中直接生成 HTML 很繁琐并不好玩(那是上个世纪90年代的 PHP 搞的事情),在现代社会,我们使用模版引擎,Flask 已经自动配置好了 Jinja2 模版,使用方法 render_template() 来渲染模版就可以了。Flask 会默认在 templates 目录里中寻找模版,我们只需要创建几个模版文件就可以了,这里我们创建 base.html, index.html 和 page.html.
$ vi app/templates/base.html
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>vpsee.com static blog</title>
</head>
<body>
<h1><a href="{{ url_for("index") }}">vpsee.com blog</a></h1>
{% block content %}
{% endblock content %}
</body>
</html>
代码里 extends “base.html” 的意思是从 base.html 里继承基本的 “骨架”。
$ vi app/templates/index.html
{% extends "base.html" %}
{% block content %}
<h2>List of pages
<ul>
{% for page in pages %}
<li>
<a href="{{ url_for("page", path=page.path) }}">{{ page.title }}</a>
</li>
{% else %}
<li>No post.</li>
{% endfor %}
</ul>
{% endblock content %}
$ vi app/templates/page.html
{% extends "base.html" %}
{% block content %}
<h2>{{ page.title }}</h2>
{{ page.html|safe }}
{% endblock content %}
Flask-FlatPages 模块会默认从 pages 目录里寻找 .md 结尾的 Markdown 文档,所以我们把静态博客的内容都放在这个目录里:
$ vi app/pages/hello-world.md title: Hello World date: 2014-10-14 tags: [general, blog] **Hello World**! $ vi app/pages/test-flatpages.md title: Test Flask FlatPages date: 2014-10-15 tags: [python, flask] Test [Flask-FlatPages](https://pythonhosted.org/Flask-FlatPages/)
运行
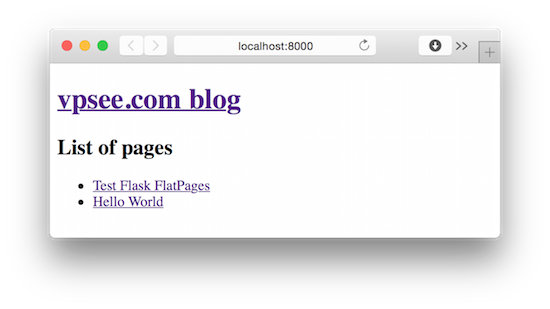
基本搞定,运行看看效果吧:
$ flask/bin/python app/blog.py * Running on http://127.0.0.1:8000/ * Restarting with reloader
静态化
到目前为止,上面的博客运行良好,但是有个问题,这个博客还不是 “静态” 的,没有生成任何 html 文件,不能直接放到 nginx/apache 这样的 web 服务器下用。所以我们需要另一个 Flask 模块 Frozen-Flask 的帮助。
安装 Frozen-Flask:
$ flask/bin/pip install frozen-flask
修改 blog.py,导入 Flask-Frozen 模块,初始化 Freezer,使用 freezer.freeze() 生成静态 HTML:
$ vi app/blog.py
...
from flask_flatpages import FlatPages
from flask_frozen import Freezer
import sys
...
flatpages = FlatPages(app)
freezer = Freezer(app)
...
if __name__ == '__main__':
if len(sys.argv) > 1 and sys.argv[1] == "build":
freezer.freeze()
else:
app.run(port=8000)
运行 blog.py build 后就在 app 目录下生成 build 目录,build 目录里面就是我们要的 HTML 静态文件:
$ flask/bin/python app/blog.py build $ ls app/ blog.py build pages static templates
更清晰的目录结构如下:
$ tree app
app
├── blog.py
├── build
│ ├── index.html
│ └── pages
│ ├── hello-world
│ │ └── index.html
│ └── test-flatpages
│ └── index.html
├── pages
│ ├── hello-world.md
│ └── test-flatpages.md
├── static
└── templates
├── base.html
├── index.html
└── page.html