Merry Christmas & a prosperous 2014
2013年12月25日 | 标签: holiday

2013年11月29日 | 标签: centos, cloud, cloudstack
又到年底,下月开始休假,所以这周基本上算今年 “努力” 的最后一周,接下来六周都不会有技术文章更新。
和 OpenStack, OpenNebula 类似,CloudStack 是另一款开源云计算平台。CloudStack 的前身是 Cloud.com 家的一款商业云计算产品(也有开源版本),2011年 Cloud.com 被 Citrix 收购,2012年的时候 Citrix 将收购的云平台 CloudStack 全部捐给了 Apache 基金会,自己则以 Citrix CloudPlatform (powered by Apache CloudStack) 的形式为客户提供商业化的云计算解决方案。
按照《OpenStack, OpenNebula, Eucalyptus, CloudStack 社区活跃度比较》的统计,貌似 CloudStack 项目的活跃程度仅次于 OpenStack. 和大多数云计算、集群软件一样,CloudStack 也是控制节点+计算节点这种架构,控制节点(cloudstack-management)用来统一管理计算节点,提供资源分配和任务,提供 API、GUI、数据库等服务;计算节点(cloudstack-agent)则用来跑虚拟机。我们需要做的是,
安装完 CentOS 6.4 系统后,升级系统并修改 hostname 后重启:
# yum update # echo "cloudstack.vpsee.com" > /etc/hostname # vi /etc/sysconfig/network NETWORKING=yes NETWORKING_IPV6=no HOSTNAME=cloudstack.vpsee.com # echo "192.168.2.150 cloudstack cloudstack.vpsee.com" >> /etc/hosts # reboot
添加 cloudstack 软件包的官方源,安装 ntp, cloudstack-management, mysql 数据库服务器:
# vi /etc/yum.repos.d/cloudstack.repo [cloudstack] name=cloudstack baseurl=http://cloudstack.apt-get.eu/rhel/4.2/ enabled=1 gpgcheck=0 # yum update # yum install ntp # yum install cloudstack-management # yum install mysql-server
修改 mysql 配置文件,加入下面几行,启动 ntp, mysql 服务并运行 mysql_secure_installation 给 mysql 设置密码:
# vi /etc/my.cnf ... [mysqld] ... innodb_rollback_on_timeout=1 innodb_lock_wait_timeout=600 max_connections=350 log-bin=mysql-bin binlog-format = 'ROW' [mysqld_safe] ... # service ntpd start # chkconfig ntpd on # service mysqld start # chkconfig mysqld on # mysql_secure_installation
修改 SELINUX 设置,并配置防火墙允许访问 mysql 的 3306 端口:
# vi /etc/selinux/config ... SELINUX=permissive ... # setenforce permissive # vi /etc/sysconfig/iptables ... -A INPUT -p tcp --dport 3306 -j ACCEPT ... # service iptables restart
使用 cloudstack-setup-databases 初始化 ClouStack 数据库,完成后运行 cloudstack-setup-management:
# cloudstack-setup-databases cloud:cloud@localhost --deploy-as=root:root -i 192.168.2.150 # cloudstack-setup-management Starting to configure CloudStack Management Server: Configure sudoers ... [OK] Configure Firewall ... [OK] Configure CloudStack Management Server ...[OK] CloudStack Management Server setup is Done!
控制节点应该和存储分开,这里为了方便,我们把 NFS 也装在这个控制节点上,并自己挂载自己的 NFS 分区:
# yum install nfs-utils # mkdir -p /export/primary # mkdir -p /export/secondary # vi /etc/exports /export *(rw,async,no_root_squash,no_subtree_check) # exportfs -a # vi /etc/sysconfig/nfs ... LOCKD_TCPPORT=32803 LOCKD_UDPPORT=32769 MOUNTD_PORT=892 RQUOTAD_PORT=875 STATD_PORT=662 STATD_OUTGOING_PORT=2020 ... # service rpcbind start # service nfs start # chkconfig nfs on # chkconfig rpcbind on # reboot # mkdir -p /mnt/primary # mkdir -p /mnt/secondary # mount -t nfs 192.168.2.150:/export/primary /mnt/primary # mount -t nfs 192.168.2.150:/export/secondary /mnt/secondary
修改防火墙配置,开放下面一些端口:
# vi /etc/sysconfig/iptables ... -A INPUT -s 192.168.2.0/24 -m state --state NEW -p udp --dport 111 -j ACCEPT -A INPUT -s 192.168.2.0/24 -m state --state NEW -p tcp --dport 111 -j ACCEPT -A INPUT -s 192.168.2.0/24 -m state --state NEW -p tcp --dport 2049 -j ACCEPT -A INPUT -s 192.168.2.0/24 -m state --state NEW -p tcp --dport 32803 -j ACCEPT -A INPUT -s 192.168.2.0/24 -m state --state NEW -p udp --dport 32769 -j ACCEPT -A INPUT -s 192.168.2.0/24 -m state --state NEW -p tcp --dport 892 -j ACCEPT -A INPUT -s 192.168.2.0/24 -m state --state NEW -p udp --dport 892 -j ACCEPT -A INPUT -s 192.168.2.0/24 -m state --state NEW -p tcp --dport 875 -j ACCEPT -A INPUT -s 192.168.2.0/24 -m state --state NEW -p udp --dport 875 -j ACCEPT -A INPUT -s 192.168.2.0/24 -m state --state NEW -p tcp --dport 662 -j ACCEPT -A INPUT -s 192.168.2.0/24 -m state --state NEW -p udp --dport 662 -j ACCEPT ... # service iptables restart # service iptables save
创建虚拟机需要有模版,这个模版可以自己做,也可以下载官方现成的。需要注意的是,官方文档中的 /usr/lib64/cloud/common/… 路径不对,应该是 /usr/share/cloudstack-common/…:
# /usr/share/cloudstack-common/scripts/storage/secondary/cloud-install-sys-tmplt -m /mnt/secondary -u http://d21ifhcun6b1t2.cloudfront.net/templates/4.2/systemvmtemplate-2013-06-12-master-kvm.qcow2.bz2 -h kvm -s -F
为了保持一致,我们在计算节点上也采用 CentOS 6.4. 在每个计算节点上都需要如下的安装和配置。升级系统并修改 hostname、重启:
# yum update # echo "cloudstack01.vpsee.com" > /etc/hostname # vi /etc/sysconfig/network NETWORKING=yes NETWORKING_IPV6=no HOSTNAME=cloudstack01.vpsee.com # echo "192.168.2.151 cloudstack01 cloudstack.vpsee.com" >> /etc/hosts # reboot
添加 cloudstack 软件包的官方源,安装 ntp, cloudstack-agent 和 kvm:
# vi /etc/yum.repos.d/cloudstack.repo [cloudstack] name=cloudstack baseurl=http://cloudstack.apt-get.eu/rhel/4.2/ enabled=1 gpgcheck=0 # yum update # yum install ntp # yum install cloudstack-agent # yum install qemu-kvm
修改 libvirt 相关配置文件,去掉下面几行的注释,注意把 auth_tcp 改成 “none”,如果需要 vnc 访问的话别忘了取消 qemu.conf 里面的 vnc_listen 相关注释,重启 libvirtd 服务使配置生效:
# vi /etc/libvirt/libvirtd.conf ... listen_tls = 0 listen_tcp = 1 tcp_port = "16509" auth_tcp = "none" mdns_adv = 0 ... # vi /etc/sysconfig/libvirtd ... LIBVIRTD_ARGS="--listen" ... # vi /etc/libvirt/qemu.conf ... vnc_listen = "0.0.0.0" ... # service libvirtd restart
别忘了让防火墙开放必要的端口:
# iptables -I INPUT -p tcp -m tcp --dport 22 -j ACCEPT # iptables -I INPUT -p tcp -m tcp --dport 1798 -j ACCEPT # iptables -I INPUT -p tcp -m tcp --dport 16509 -j ACCEPT # iptables -I INPUT -p tcp -m tcp --dport 5900:6100 -j ACCEPT # iptables -I INPUT -p tcp -m tcp --dport 49152:49216 -j ACCEPT # iptables-save > /etc/sysconfig/iptables
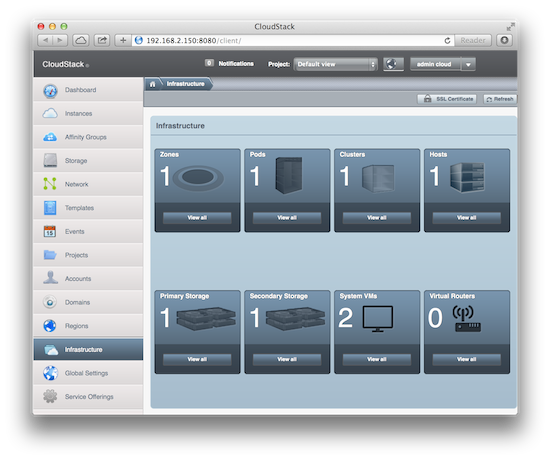
打开浏览器,访问控制节点 http://192.168.2.150:8080/client/ 就会看到登录界面,默认用户名和密码是 admin/password,登录后修改密码、做一些配置后就可以开始用了:
2013年11月23日 | 标签: dom0, domu, iptables, xen, xend
作为 Xen VPS 服务商,我们分配独立的 IP 地址给 VPS,我们不希望 VPS 用户自己能随便修改 IP 地址,因为这样有可能和其他用户的 IP 地址造成冲突,而且造成管理上的不便,所以需要绑定 IP 给某个 VPS.
解决这个问题的办法有很多,从路由器、防火墙、操作系统、Xen 等层面都可以做限制。这里介绍的两个简单方法都是从 dom0 入手:一个是在 dom0 上利用 Xen 配置;一个是在 dom0 上利用 iptables.
Xen 上有个 antispoof 配置选项就是来解决这个问题的,不过默认配置没有打开这个 antispoof 选项,需要修改:
# vi /etc/xen/xend-config.sxp ... (network-script 'network-bridge antispoof=yes') ...
修改 /etc/xen/scripts/vif-common.sh 里面的 frob_iptable() 函数部分,加上 iptables 一行:
# vi /etc/xen/scripts/vif-common.sh
function frob_iptable()
{
...
iptables -t raw "$c" PREROUTING -m physdev --physdev-in "$vif" "$@" -j NOTRACK
}
修改完 Xen 配置后还需要修改 domU 的配置,给每个 domU 分配固定 IP 和 MAC 地址,还有 vif 名字:
# vi /etc/xen/vm01 ... vif = [ "vifname=vm01,mac=00:16:3e:7c:1f:6e,ip=172.16.39.105,bridge=xenbr0" ] ...
很多系统上 iptables 在默认情况下都不会理会网桥上的 FORWARD 链,所以需要修改内核参数确保 bridge-nf-call-iptables=1,把这个修改可以放到 antispoofing() 函数里,这样每次 Xen 配置网络的时候会自动配置内核参数:
# vi /etc/xen/scripts/network-bridge
antispoofing () {
echo 1 > /proc/sys/net/bridge/bridge-nf-call-iptables
...
}
修改完毕后测试的话需要关闭 domU,重启 iptables 和 xend 服务,再启动 domU.
# xm shutdown vm01 # /etc/init.d/iptables restart # /etc/init.d/xend restart # xm create vm01
上面的方法在 Xen 3.x 上 测试有效,有人说在 Xen 4.x 上行不通,我们下面将要介绍的方法绕开了 Xen 配置,直接从 iptables 限制,在 Xen 3.x 和 Xen 4.x 上应该都可以用。
首先在 dom0 上确定 iptables 已经开启,这里需要注意的是一定要在每个 domU 的配置文件中的 vif 部分加上 vifname, ip, mac,这样才能在 iptables 规则里面明确定义:
# /etc/init.d/iptables restart # vi /etc/xen/vm01 ... vif = [ "vifname=vm01,mac=00:16:3e:7c:1f:6e,ip=172.16.39.105,bridge=xenbr0" ] ... # vi /etc/iptables-rules *filter :INPUT ACCEPT [0:0] :FORWARD ACCEPT [0:0] :OUTPUT ACCEPT [0:0] # The antispoofing rules for domUs -A FORWARD -m state --state RELATED,ESTABLISHED -m physdev --physdev-out vm01 -j ACCEPT -A FORWARD -p udp -m physdev --physdev-in vm01 -m udp --sport 68 --dport 67 -j ACCEPT -A FORWARD -s 172.16.39.105/32 -m physdev --physdev-in vm01 -j ACCEPT -A FORWARD -d 172.16.39.105/32 -m physdev --physdev-out vm01 -j ACCEPT # If the IP address is not allowed on that vif, log and drop it. -A FORWARD -m limit --limit 15/min -j LOG --log-prefix "Dropped by firewall: " --log-level 7 -A FORWARD -j DROP # The access rules for dom0 -A INPUT -j ACCEPT COMMIT # iptables-restore < /etc/iptables.rules
当然,别忘了:
# echo 1 > /proc/sys/net/bridge/bridge-nf-call-iptables
2013年11月15日 | 标签: docker
Docker 的命令行就已经很好用了,如果非要加上基于 Web 的管理界面的话也有一些选择,如 DockerUI (Angular.js), Dockland (Ruby), Shipyard (Python/Django) 等,不过目前来看 Shipyard 项目要活跃一点,Shipyard 支持多 host,可以把多个 Docker host 上的 containers 统一管理;可以查看 images,甚至 build images;并提供 RESTful API 等等。
Shipyard 要管理和控制 Docker host 的话需要先修改 Docker host 上的默认配置使其支持远程管理。修改配置文件 docker.conf,把 /usr/bin/docker -d 这行加上 -H tcp://0.0.0.0:4243 -H unix:///var/run/docker.sock 参数:
$ sudo vi /etc/init/docker.conf
description "Run docker"
start on filesystem or runlevel [2345]
stop on runlevel [!2345]
respawn
script
/usr/bin/docker -d -H tcp://0.0.0.0:4243 -H unix:///var/run/docker.sock
end script
可以独立安装 Shipyard 也可以把 Shipyard 安装在一个 Docker 容器里。如果有人提供了 Docker 镜像甚至连安装的过程也省了,直接下载运行就可以了,Shipyard 的作者就提供了这么一个镜像(需要注意的是这里的默认登录用户名和密码是 admin/shipyard):
$ sudo docker pull shipyard/shipyard $ sudo docker run -i -t -d -p 80:80 -p 8000:8000 ehazlett/shipyard
如果不想使用上面的 Docker 镜像,想直接安装在服务器上的话也不是很麻烦,可以自行设置登录用户名和密码:
$ git clone https://github.com/shipyard/shipyard.git $ cd shipyard/ $ sudo pip install -r requirements.txt $ sudo python manage.py syncdb --noinput $ sudo python manage.py migrate $ sudo python manage.py createsuperuser Username (leave blank to use 'root'):admin Email address: test@vpsee.com Password: Password (again): Superuser created successfully. $ sudo python manage.py runserver 0.0.0.0:8000 Validating models... 0 errors found November 15, 2013 - 03:46:23 Django version 1.6, using settings 'shipyard.settings' Starting development server at http://0.0.0.0:8000/ Quit the server with CONTROL-C.
开另一个终端或 ssh 会话输入以下命令:
$ sudo python manage.py celery worker -B --scheduler=djcelery.schedulers.DatabaseScheduler -E
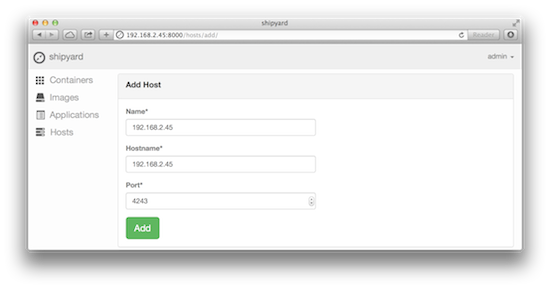
安装成功后打开浏览器访问 http://192.168.2.45:8000/ 就可以看到登录界面,输入用户名和密码登录成功后到左边的 Hosts 里添加一个 Docker host,输入 Docker host 的 IP 地址就可以了:
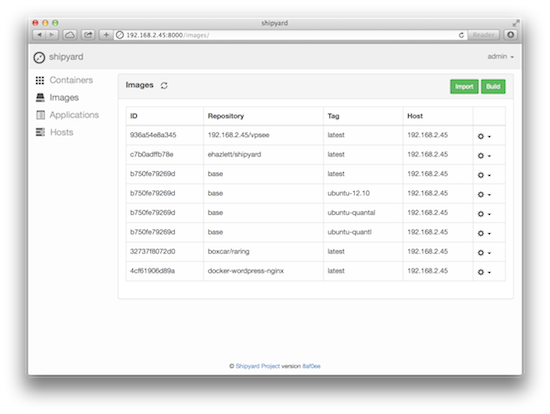
成功添加一个 Docker host 后就可以访问到这台 host 上正在运行的 containers 以及保存的 images 了:
关于 Docker 的介绍这里就省了,Docker 在其相关领域的火爆程度不亚于今年汽车行业里的特斯拉,docCloud 甚至把公司名都改成了 Docker, Inc. 好东西总是传播很快,我们现在已经有客户在 VPS 上用 Docker 来部署应用了。不了解 Docker 的小伙伴们可以看看 使用 Docker/LXC 迅速启动一个桌面系统 开头部分的介绍。
和初次接触 Xen/KVM 虚拟技术的体验不同,Docker 不用自己动手制作镜像,官方已经提供了很多版本的 Linux 镜像,直接从官方仓库(Public Repositories)下载就可以了。如果考虑到安全性和速度,我们可能会想在自己局域网里架设一个私有仓库(Private Repositories)来放我们自己的镜像,Docker-Registry 正是我们需要的工具。
用 git 下载源码后修改配置文件 config.yml,把 storage_path 部分改成 Docker 镜像仓库的存放地点:
$ git clone https://github.com/dotcloud/docker-registry
$ cd docker-registry
$ cp config_sample.yml config.yml
$ vi config.yml
...
# This is the default configuration when no flavor is specified
dev:
storage: local
storage_path: /home/vpsee/registry
loglevel: debug
...
$ mkdir /home/vpsee/registry
安装一些必要软件包和一些 Docker-Registry 需要用到的 Python 工具和库:
$ sudo apt-get install build-essential python-dev libevent-dev python-pip libssl-dev $ sudo pip install -r requirements.txt
Docker-Registry 实际上是个基于 Flask 的 web app,安装成功后就可以这样运行了:
$ sudo gunicorn --access-logfile - --debug -k gevent -b 0.0.0.0:80 -w 1 wsgi:application
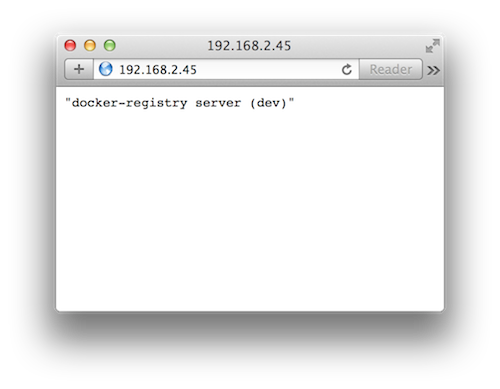
打开浏览器,访问 IP 地址就可以看到 docker-registry 私有仓库在运行了:
查看一下现有系统上已经有了哪些镜像:
$ sudo docker images REPOSITORY TAG ID CREATED SIZE vpsee/ubuntu latest 936a54e8a345 2 weeks ago 12.29 kB (virtual 327.8 MB) ubuntu latest 8dbd9e392a96 6 months ago 131.5 MB (virtual 131.5 MB) ubuntu precise 8dbd9e392a96 6 months ago 131.5 MB (virtual 131.5 MB) ubuntu quantal b750fe79269d 7 months ago 24.65 kB (virtual 180.1 MB)
我们打算把 vpsee/ubuntu 这个镜像(ID 是 936a54e8a345)上传(push)到我们刚创建的私有仓库里(这个私有仓库的 IP 地址是 192.168.2.45),会看到提示 Username/Password,初次 push 的话,可以自己设置用户名和密码:
$ sudo docker tag 936a54e8a345 192.168.2.45/vpsee $ sudo docker push 192.168.2.45/vpsee Username: vpsee Password: Email: docker@vpsee.com Account created. Please use the confirmation link we sent to your e-mail to activate it. The push refers to a repository [192.168.2.45/vpsee] (len: 1) Processing checksums Sending image list Pushing repository 192.168.2.45/vpsee (1 tags) Pushing 8dbd9e392a964056420e5d58ca5cc376ef18e2de93b5cc90e868a1bbc8318c1c Buffering to disk 58266504/? (n/a) Pushing 58.27 MB/58.27 MB (100%)
完成 push 后,我们的私有仓库就有了第一个镜像了:
$ sudo docker images REPOSITORY TAG ID CREATED SIZE vpsee/ubuntu latest 936a54e8a345 2 weeks ago 12.29 kB (virtual 327.8 MB) ubuntu latest 8dbd9e392a96 6 months ago 131.5 MB (virtual 131.5 MB) ubuntu precise 8dbd9e392a96 6 months ago 131.5 MB (virtual 131.5 MB) ubuntu quantal b750fe79269d 7 months ago 24.65 kB (virtual 180.1 MB) 192.168.2.45/vpsee latest 936a54e8a345 2 weeks ago 12.29 kB (virtual 327.8 MB)
以后只要 docker pull 192.168.2.45/vpsee 就可以从我们自己的私有仓库下载和运行镜像了,本地网络速度当然会快很多。
上周在一台 OpenNebula 服务器上操作虚拟机镜像,正在生成和比对镜像文件的 md5 指纹:
# ls -l test.img -rw-r--r-- 1 root root 10486808576 Oct 12 02:21 test.img # md5sum test.img
在另一个窗口清理文件的时候不小心误删了这个 10GB 左右的镜像文件:
# rm test.img
这时候行动迅速的话还有时间拯救,因为服务器繁忙,执行 rm 删除 10GB 大文件的时候需要一点时间,利用这点时间切换到另一窗口使用 Ctrl+Z 立刻暂停 md5sum:
[1]+ Stopped md5sum test.img
这里利用的一个原理就是,如果有其他程序正在使用这个文件的话,Linux 不会真正删除这个文件(即使执行了 rm 命令)。我们在删除命令 rm 执行完之前暂停 md5sum,这样 test.img 就一直会被 md5um 占用而不会真正被 rm 删除。
使用 jobs 可以看到被暂停的 md5sum 的进程号 30888,然后查看这个进程打开了哪些文件:
# jobs -l [1]+ 30888 Stopped md5sum test.img # ls -l /proc/30888/fd total 0 lrwx------ 1 root root 64 Oct 22 04:04 0 -> /dev/pts/3 lrwx------ 1 root root 64 Oct 22 04:04 1 -> /dev/pts/3 lrwx------ 1 root root 64 Oct 22 04:04 2 -> /dev/pts/3 lr-x------ 1 root root 64 Oct 22 04:04 3 -> /root/test.img (deleted)
使用 cp 就可以把误删的文件拷贝出来:
# cp /proc/30888/fd/3 save.img # ls -l save.img -rw-r--r-- 1 root root 10486808576 Oct 22 06:11 save.img
误删文本文件的话可以尝试用 grep 恢复,误删 exe/doc/png/jpg/gif 之类的文件的话,可以用第三方 ext2/ext3 文件恢复工具 TestDisk, PhotoRec 等帮助恢复文件。
2013年10月23日 | 标签: Mac, mac os x
现在升级操作系统这种在以前看来很麻烦的事情变得越来越简单,就像升级一次应用程序一样。升级 Tiger 到 Snow Leopard 从订购安装盘到完成升级花了几天的时间,Snow Leopard 时代就不需要安装光盘了,直接到 App Store 购买后下载升级,这次升级到 Mavericks 更快,在苹果发布会宣布的同一天就完成了升级,昨天得知 OS X 10.9 Mavericks 免费后惊呆了,立刻 Software Update… 果然看到 FREE UPGRADE 按钮:
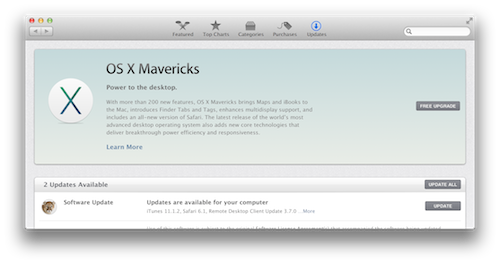
下载速度很快,5.29GB 的系统镜像下载+安装不到一小时就搞定了。

据说新版系统有200多项改进,玩了两下没发现什么特别激动的,小改进挺多,iCloud Keychain 能方便记住各种密码并且自动同步到其他 Apple 设备上,在 Mac 上输入的密码在 iPad/iPhone 上就不用输入了,很方便;Finder 增加了 Tabs,不用开多个 Finder 窗口了;新系统增加了两个比较有用的应用程序,iBooks 和 Maps;Calendar 改进了很多,类似 iOS 7 的界面风格;点击 Battery 会看到哪些应用程序很耗电(Apps Using Significant Energy),这个能方便用户在需要的时候关闭这些程序 …
这次宣布免费的重量级应用还有 Pages, Numbers, Keynote. 苹果把操作系统和办公套件(Mac OS X + Pages/Numbers/Keynote)都免费了,难道不知道微软是靠 Windows + Word/Excel/Powerpoint 吃饭的么?这算不算 “走别人的路,让别人无路可走” 呢~
2013年10月17日 | 标签: linux, lsyncd, rsync, ubuntu
自动同步本地服务器(或 VPS)上的目录到另一台或多台远程服务器的办法和工具有很多,最简单的办法可能是用 rsync + cron(参考:用 VPS 给博客做镜像),这种办法有个问题就是 rsync 只能在固定时间间隔里被 cron 调用,如果时间间隔设的太短,频繁 rsync 会增加服务器负担;如果时间间隔设的太长,可能数据不能及时同步。今天介绍的 lsyncd 采用了 Linux 内核(2.6.13 及以后)里的 inotify 触发机制,这种机制可以做到只有在需要(变化)的时候才去同步。lsyncd 密切监测本地服务器上的参照目录,当发现目录下有文件或目录变更后,立刻通知远程服务器,并通过 rsync 或 rsync+ssh 方式实现文件同步。lsyncd 默认同步触发条件是每20秒或者每积累到1000次写入事件就触发一次,当然,这个触发条件可以通过配置参数调整。
lsyncd 已经在 Ubuntu 的官方源里,安装很容易:
$ sudo apt-get update $ sudo apt-get install lsyncd
lsyncd 安装后没有自动生成所需要的配置文件和目录,需要手动创建:
$ sudo mkdir /etc/lsyncd
$ sudo touch /etc/lsyncd/lsyncd.conf.lua
$ sudo mkdir /var/log/lsyncd
$ sudo touch /var/log/lsyncd/lsyncd.{log,status}
配置 lsyncd,注意 source, host, targetdir 部分,依次是本地需要同步到远程的目录(源头),远程机器的 IP,远程目录(目标):
$ sudo vi /etc/lsyncd/lsyncd.conf.lua
settings {
logfile = "/var/log/lsyncd/lsyncd.log",
statusFile = "/var/log/lsyncd/lsyncd.status"
}
sync {
default.rsyncssh,
source = "/home/vpsee/local",
host = "192.168.2.5",
targetdir = "/remote"
}
配置本地机器和远程机器 root 帐号无密码 ssh 登陆,并在远程机器上(假设 IP 是 192.168.2.5)创建一个 /remote 目录:
$ sudo su # ssh-keygen -t rsa # ssh-copy-id root@192.168.2.5 # ssh 192.168.2.5 # mkdir /remote
配置好后就可以在本地机器上启动 lsyncd 服务了,启动服务后本地机器 /home/vpsee/local 下的目录会自动同步到远程机器的 /remote 目录下:
$ sudo service lsyncd restart
除了同步本地目录到远程目录外,lsyncd 还可以轻松做到同步本地目录到本地另一目录,只要修改配置文件就可以了:
$ sudo vi /etc/lsyncd/lsyncd.conf.lua
settings {
logfile = "/var/log/lsyncd/lsyncd.log",
statusFile = "/var/log/lsyncd/lsyncd.status"
}
sync {
default.rsync,
source = "/home/vpsee/local",
target = "/localbackup"
}
$ sudo service lsyncd restart
2013年10月10日 | 标签: linux kernel, mysql, oom killer
最近有位 VPS 客户抱怨 MySQL 无缘无故挂掉,还有位客户抱怨 VPS 经常死机,登陆到终端看了一下,都是常见的 Out of memory 问题。这通常是因为某时刻应用程序大量请求内存导致系统内存不足造成的,这通常会触发 Linux 内核里的 Out of Memory (OOM) killer,OOM killer 会杀掉某个进程以腾出内存留给系统用,不致于让系统立刻崩溃。如果检查相关的日志文件(/var/log/messages)就会看到下面类似的 Out of memory: Kill process 信息:
... Out of memory: Kill process 9682 (mysqld) score 9 or sacrifice child Killed process 9682, UID 27, (mysqld) total-vm:47388kB, anon-rss:3744kB, file-rss:80kB httpd invoked oom-killer: gfp_mask=0x201da, order=0, oom_adj=0, oom_score_adj=0 httpd cpuset=/ mems_allowed=0 Pid: 8911, comm: httpd Not tainted 2.6.32-279.1.1.el6.i686 #1 ... 21556 total pagecache pages 21049 pages in swap cache Swap cache stats: add 12819103, delete 12798054, find 3188096/4634617 Free swap = 0kB Total swap = 524280kB 131071 pages RAM 0 pages HighMem 3673 pages reserved 67960 pages shared 124940 pages non-shared
Linux 内核根据应用程序的要求分配内存,通常来说应用程序分配了内存但是并没有实际全部使用,为了提高性能,这部分没用的内存可以留作它用,这部分内存是属于每个进程的,内核直接回收利用的话比较麻烦,所以内核采用一种过度分配内存(over-commit memory)的办法来间接利用这部分 “空闲” 的内存,提高整体内存的使用效率。一般来说这样做没有问题,但当大多数应用程序都消耗完自己的内存的时候麻烦就来了,因为这些应用程序的内存需求加起来超出了物理内存(包括 swap)的容量,内核(OOM killer)必须杀掉一些进程才能腾出空间保障系统正常运行。用银行的例子来讲可能更容易懂一些,部分人取钱的时候银行不怕,银行有足够的存款应付,当全国人民(或者绝大多数)都取钱而且每个人都想把自己钱取完的时候银行的麻烦就来了,银行实际上是没有这么多钱给大家取的。
内核检测到系统内存不足、挑选并杀掉某个进程的过程可以参考内核源代码 linux/mm/oom_kill.c,当系统内存不足的时候,out_of_memory() 被触发,然后调用 select_bad_process() 选择一个 “bad” 进程杀掉,如何判断和选择一个 “bad” 进程呢,总不能随机选吧?挑选的过程由 oom_badness() 决定,挑选的算法和想法都很简单很朴实:最 bad 的那个进程就是那个最占用内存的进程。
/**
* oom_badness - heuristic function to determine which candidate task to kill
* @p: task struct of which task we should calculate
* @totalpages: total present RAM allowed for page allocation
*
* The heuristic for determining which task to kill is made to be as simple and
* predictable as possible. The goal is to return the highest value for the
* task consuming the most memory to avoid subsequent oom failures.
*/
unsigned long oom_badness(struct task_struct *p, struct mem_cgroup *memcg,
const nodemask_t *nodemask, unsigned long totalpages)
{
long points;
long adj;
if (oom_unkillable_task(p, memcg, nodemask))
return 0;
p = find_lock_task_mm(p);
if (!p)
return 0;
adj = (long)p->signal->oom_score_adj;
if (adj == OOM_SCORE_ADJ_MIN) {
task_unlock(p);
return 0;
}
/*
* The baseline for the badness score is the proportion of RAM that each
* task's rss, pagetable and swap space use.
*/
points = get_mm_rss(p->mm) + p->mm->nr_ptes +
get_mm_counter(p->mm, MM_SWAPENTS);
task_unlock(p);
/*
* Root processes get 3% bonus, just like the __vm_enough_memory()
* implementation used by LSMs.
*/
if (has_capability_noaudit(p, CAP_SYS_ADMIN))
adj -= 30;
/* Normalize to oom_score_adj units */
adj *= totalpages / 1000;
points += adj;
/*
* Never return 0 for an eligible task regardless of the root bonus and
* oom_score_adj (oom_score_adj can't be OOM_SCORE_ADJ_MIN here).
*/
return points > 0 ? points : 1;
}
上面代码里的注释写的很明白,理解了这个算法我们就理解了为啥 MySQL 躺着也能中枪了,因为它的体积总是最大(一般来说它在系统上占用内存最多),所以如果 Out of Memeory (OOM) 的话总是不幸第一个被 kill 掉。解决这个问题最简单的办法就是增加内存,或者想办法优化 MySQL 使其占用更少的内存,除了优化 MySQL 外还可以优化系统(优化 Debian 5,优化 CentOS 5.x),让系统尽可能使用少的内存以便应用程序(如 MySQL) 能使用更多的内存,还有一个临时的办法就是调整内核参数,让 MySQL 进程不容易被 OOM killer 发现。
我们可以通过一些内核参数来调整 OOM killer 的行为,避免系统在那里不停的杀进程。比如我们可以在触发 OOM 后立刻触发 kernel panic,kernel panic 10秒后自动重启系统。
# sysctl -w vm.panic_on_oom=1 vm.panic_on_oom = 1 # sysctl -w kernel.panic=10 kernel.panic = 10 # echo "vm.panic_on_oom=1" >> /etc/sysctl.conf # echo "kernel.panic=10" >> /etc/sysctl.conf
从上面的 oom_kill.c 代码里可以看到 oom_badness() 给每个进程打分,根据 points 的高低来决定杀哪个进程,这个 points 可以根据 adj 调节,root 权限的进程通常被认为很重要,不应该被轻易杀掉,所以打分的时候可以得到 3% 的优惠(adj -= 30; 分数越低越不容易被杀掉)。我们可以在用户空间通过操作每个进程的 oom_adj 内核参数来决定哪些进程不这么容易被 OOM killer 选中杀掉。比如,如果不想 MySQL 进程被轻易杀掉的话可以找到 MySQL 运行的进程号后,调整 oom_score_adj 为 -15(注意 points 越小越不容易被杀):
# ps aux | grep mysqld mysql 2196 1.6 2.1 623800 44876 ? Ssl 09:42 0:00 /usr/sbin/mysqld # cat /proc/2196/oom_score_adj 0 # echo -15 > /proc/2196/oom_score_adj
当然,如果需要的话可以完全关闭 OOM killer(不推荐用在生产环境):
# sysctl -w vm.overcommit_memory=2 # echo "vm.overcommit_memory=2" >> /etc/sysctl.conf
我们知道了在用户空间可以通过操作每个进程的 oom_adj 内核参数来调整进程的分数,这个分数也可以通过 oom_score 这个内核参数看到,比如查看进程号为981的 omm_score,这个分数被上面提到的 omm_score_adj 参数调整后(-15),就变成了3:
# cat /proc/981/oom_score 18 # echo -15 > /proc/981/oom_score_adj # cat /proc/981/oom_score 3
下面这个 bash 脚本可用来打印当前系统上 oom_score 分数最高(最容易被 OOM Killer 杀掉)的进程:
# vi oomscore.sh
#!/bin/bash
for proc in $(find /proc -maxdepth 1 -regex '/proc/[0-9]+'); do
printf "%2d %5d %s\n" \
"$(cat $proc/oom_score)" \
"$(basename $proc)" \
"$(cat $proc/cmdline | tr '\0' ' ' | head -c 50)"
done 2>/dev/null | sort -nr | head -n 10
# chmod +x oomscore.sh
# ./oomscore.sh
18 981 /usr/sbin/mysqld
4 31359 -bash
4 31056 -bash
1 31358 sshd: root@pts/6
1 31244 sshd: vpsee [priv]
1 31159 -bash
1 31158 sudo -i
1 31055 sshd: root@pts/3
1 30912 sshd: vpsee [priv]
1 29547 /usr/sbin/sshd -D
2013年10月3日 | 标签: kernel, linux, sysrq
最近有台 NFS 服务器挂机,可以 ping 通,但不能 ssh 登陆,也不能通过本地终端登陆,只能重启了。我们一般处理文件服务器这种类型的重启都格外小心,不到迫不得已不会直接硬重启。Linux 运行过程中(为了提高性能)会把大量的数据暂时放在内存缓存中,而不是实时同步写入到磁盘,Linux 根据情况只有在需要(触发某条件)的时候才写入磁盘,所以这个时候挂机,数据还留在内存,没有办法及时写到磁盘,强制断电重启会造成数据不一致、部分数据丢失、文件系统损坏等。
为了在这样的情况下实现安全重启,我们可以利用 SysRq,当然有个条件是,系统虽然罢工停止了对大部分服务的响应,但仍然能处理键盘的中断请求。SysRq (System request) 常被称为 Magic SysRq key,在 Linux 下它被定义为一系列按键组合,之所以说它 magic,是因为它常能在系统挂起、多数服务都无法响应的时候做点事(预定义的操作),而且能在磁盘数据安全的情况下完成重启,除此之外还能捕获一些有用的系统运行信息。
首先确认当前使用的 Linux 内核支持 SysRq:
# grep "CONFIG_MAGIC_SYSRQ" /boot/config-`uname -r` CONFIG_MAGIC_SYSRQ=y
如果系统默认关闭了 kernel.sysrq 的话,需要打开。为了保证每次系统重启内核参数都生效,建议把配置写到 sysctl.conf 文件里:
# sysctl kernel.sysrq kernel.sysrq = 0 # sysctl -w kernel.sysrq=1 kernel.sysrq = 1 # vi /etc/sysctl.conf ... # Controls the System Request debugging functionality of the kernel kernel.sysrq = 1 ...
SysRq 配置好后就可以开始用了。SysRq 安全重启的推荐按键组合是 Alt + SysRq + R-E-I-S-U-B,先按下 Alt 键和 SysRq 键,然后依次按下 R E I S U B 键(不区分大小写)。这个 R E I S U B 序列组合的意思是:
R – 把键盘设置为 ASCII 模式
E – 向除 init 外所有进程发送 SIGTERM 信号
I – 向除 init 外所有进程发送 SIGKILL 信号
S – 磁盘缓冲区同步
U – 重新挂载为只读模式
B – 重启系统
需要注意的是这些按键之间有顺序,而且按键之间有时间间隔(因为要等待前一个操作的完成),推荐的时间间隔是 R – 1 秒 – E – 30 秒 – I – 10 秒 – S – 5 秒 – U – 5 秒 – B.
我们通常只在意数据是否安全的同步到了磁盘,所以我们一般只用 S-B 组合,按下 Alt + SysRq + S 后等待 Emergency Sync complete 提示,同步完成确认后用 Alt + SysRq + B 立刻重启。